智能化的知识管理:大模型在知识图谱构建中的突破性应用
知识图谱是一种以图形结构组织数据的知识表示形式,其中,概念、事件、实体等知识单元通过节点呈现,而它们之间的各种关系则通过边来描述。知识图谱的显著特点在于,通过关系的定义,为节点提供了丰富的上下文信息,从而在多义词的语义理解、实体区分等方面发挥着关键作用。例如,在谷歌搜索中,知识图谱能够准确区分“苹果”这一品牌与水果的不同含义。知识图谱的应用范围广泛,涵盖了零售业、搜索引擎优化、反洗钱以及医疗保健等多个领域,尤其在产品推荐系统中展现出其独特的价值。尽管知识图谱的应用前景广阔,但其构建过程却面临着诸多挑战,如成本高昂、构建周期长等。为应对这些挑战,近年来,自动构建知识图谱的研究成为热点。特别是,随着大型语言模型(LLM),如GPT-4等技术的发展,其在语言理解和处理方面的卓越能力,为知识图谱的自动构建提供了新的可能性。本文首先将探讨知识图谱构建中的主要难题,其次,将知识图谱与LLM在知识库构建方面进行对比分析。最后,文章将对现有利用LLM进行自动知识图谱构建的方法进行综述。传统的知识图谱构建方法主要依赖于众包和文本挖掘技术。众包知识图谱的典型例子包括WordNet和ConceptNet,这些知识图谱通过大量人力资源构建而成,但它们通常局限于预定义的关系集合。另一方面,基于文本挖掘的技术从文档中提取知识,其能力受限于文本中明确表述的关系。这种方法涉及多个复杂的步骤,包括共指消解、命名实体识别等。知识图谱的构建过程具有高度的复杂性,这一点在为特定领域或应用构建定制化知识图谱时尤为突出。由于不同领域所采用的概念和术语各不相同,不存在一种普适的方法来创建知识图谱。特定领域的知识图谱构建还面临着独特的挑战。例如,在服务计算领域,知识图谱对于资源管理、个性化推荐和客户洞察等方面极为有用。然而,这些应用场景通常要求知识图谱整合来自多个领域的知识和概念,而所需的数据往往是高度分散且缺乏注释的。这些因素显著增加了构建知识图谱所需的时间、资源和成本。知识图谱和大型语言模型(LLM)均可用于知识的检索。在知识图谱中,通过查询相关联的节点来确定答案;而在LLM中,模型接收提示并填写缺失的部分来完成句子。例如,GPT-4和BERT等LLM因其卓越的语言理解能力而备受瞩目。这些模型随着规模的不断扩大和海量数据的训练,积累了广泛的知识。如今,许多用户倾向于通过ChatGPT等平台提出问题,而不是传统的Google搜索。学术界和工业界的关注点转向了探讨LLM(如GPT)是否有可能取代知识图谱(如谷歌知识图谱)成为主要的知识来源。进一步的研究揭示,尽管大型语言模型(LLMs)拥有更多的基础世界知识,但它们在回忆关系性事实和推断行动与事件之间的关系方面存在困难。尽管大型语言模型有许多优势,但它们也面临以下挑战:
- 幻觉:大型语言模型有时会产生令人信服但不正确的信息。相反,知识图谱提供基于其事实数据源的结构化和明确的知识。
- 推理能力有限:大型语言模型难以理解和使用支持证据来得出结论,特别是在数值计算或符号推理方面。知识图谱中捕捉的关系允许更好的推理能力。
- 缺乏领域知识:虽然大型语言模型在大量通用数据上进行训练,但它们缺乏特定领域的知识,如医学或科学报告中的特定技术术语。与此同时,可以为特定领域构建知识图谱。
- 知识过时:大型语言模型训练成本高昂且不经常更新,导致它们的知识随时间变得过时。另一方面,知识图谱有一个更直接的更新过程,不需要重新训练。
- 偏见、隐私和毒性:大型语言模型可能会给出有偏见或冒犯性的回答,而知识图谱通常建立在没有这些偏见的可靠数据源之上。
知识图谱不会遇到这些问题,并且展现出更好的一致性、推理能力和可解释性,尽管它们也有自己的一套限制。除了之前讨论过的问题,知识图谱还缺乏大型语言模型(LLMs)因其无监督训练过程而享有的灵活性。因此,已经有众多的研究工作旨在合并LLMs和知识图谱。尽管知识图谱拥有引导LLMs朝向更高精度的能力,LLMs也可以在构建过程中帮助知识图谱进行知识提取,提高知识图谱的质量。合并这两个概念有几种方法:
- 使用LLMs辅助自动构建知识图谱:LLMs可以从数据中提取知识以填充知识图谱。关于此方法的更多细节将在下面讨论。
- 教导LLMs从知识图谱中搜索知识:如下图所示,知识图谱可以增强LLMs的推理过程,使LLMs能够得出更准确的答案。
- 将它们结合成知识图谱增强的预训练语言模型(KGPLMs):这些方法旨在将知识图谱纳入LLMs的训练过程中。
(a) 仅靠LLM可能还不够 (b) 通过知识图谱,可以增强LLM的推理过程2019年提出的一个早期方法是COMET(或COMmonsEnse Transformers),它使用了一个微调过的生成型LLM,这里是GPT,通过在给定头实体和关系的情况下生成尾实体来构建知识图谱。在下图中的“种子”和“关系”给出后,COMET生成了“完成”响应,然后由人类评估这些响应的合理性。这些种子-关系-完成三元组可以用来形成知识图谱。例如,“piece”和“machine”可以通过“PartOf”关系形成两个相连的节点。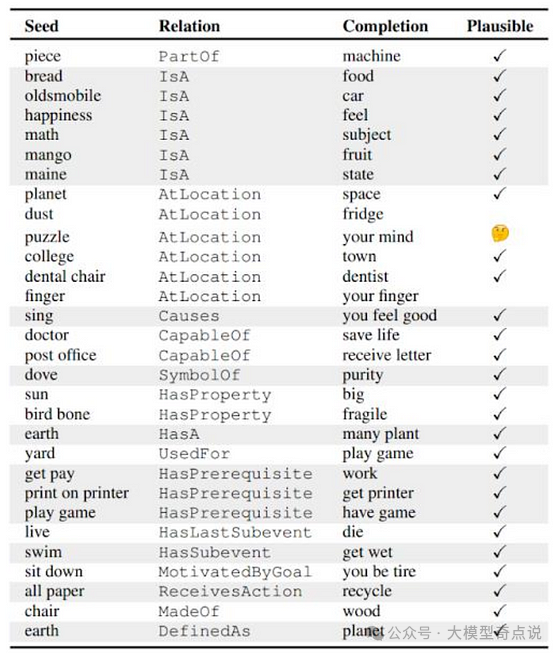
“完成”列中的响应由 COMET 生成,给定“seed”和“relation”为了避开与手动数据注释相关的努力和成本,专门针对服务领域构建了一个名为BEAR的知识图谱,使用ChatGPT进行开发。为此,创建了一个特定于该领域的本体,它作为知识图谱的基础,并确定了稍后应该填充到知识图谱中的概念和特征。然后提示ChatGPT从非结构化文本数据中提取相关内容和关系,如下图所示。自动提取的信息随后被纳入知识图谱中以构建它。ChatGPT用于从BEAR模型中的文本数据中提取信息Kommineni等人最近再次提出使用ChatGPT作为信息提取器,在他们的知识图谱构建方法中使用ChatGPT-3.5,并在两个阶段由人类领域专家验证结果,如下图所示。这种方法与之前的方法的区别在于,LLMs在这里扮演了更积极的角色。从特定数据集开始,提示ChatGPT生成能力问题(CQs),这些问题是对数据的抽象级问题。通过提示ChatGPT从CQs中提取概念和关系来创建一个本体。从数据中检索CQs的答案并交给ChatGPT,指示其提取关键实体、关系和概念,并将它们映射到本体上以构建知识图谱。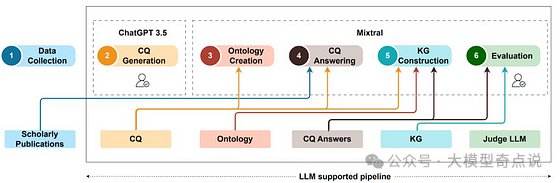
本文讨论的最后一个方法旨在直接从LLMs本身提取信息。Shibo Hao等人认识到,在LLMs的初始训练中存储了大量的知识,这些知识可以被利用。下图显示了获取LLM知识的步骤。该过程从初始提示和少至两个示例实体对开始。采用文本释义模型来对提示进行释义,并从原始提示中派生出修改后的提示。随后,在LLM中搜索与这组提示相对应的实体对。使用搜索和重新评分的方法,提取最相关的对以形成知识图谱,其中对中的实体作为节点,提示作为关系。这种方法使得生成的知识图谱具有更好的关系质量,因为派生的关系具有传统构建的知识图谱中未见的几个特点:
- 关系可能很复杂,例如,“A 有能力,但不擅长 B”。
- 关系可能涉及两个以上的实体,例如“A 可以在 C 处执行 B”。
有趣的是,使用LLMs构建知识图谱还提供了一种新方法来可视化和量化LLMs内部捕获的知识。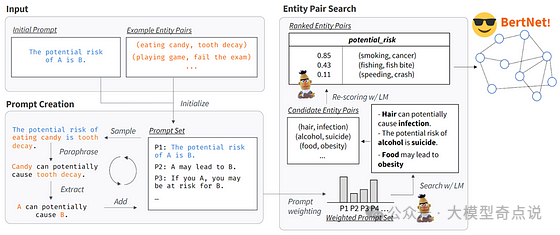
LLMs构建知识图谱的优势包括:1.表示复杂关系;2.提升关系质量;3.易于更新和扩展;4.增强知识可解释性;5.实现知识多样性和全面性;6.减少人工干预。
总之,我们讨论了知识图谱和大型语言模型(LLMs)作为知识库的潜力。知识图谱在捕捉关系方面表现出色,并且具有更强的推理能力,但构建起来困难且成本高昂。另一方面,LLMs包含广泛的知识,但容易出现偏见、幻觉和其他问题。它们在针对特定领域进行微调或适配时也计算成本昂贵。为了利用这两种方法的优势,可以通过几种方式将知识图谱和LLMs整合在一起。在本文中,我们专注于使用LLMs来辅助自动构建知识图谱。特别是,我们回顾了四个例子,包括早期的COMET模型,使用ChatGPT作为BEAR中的信息提取器,以及直接从LLMs中获取知识。这些方法代表了结合知识图谱和LLMs的优势,以增强知识表示的有希望的前进道路。
- What is a Knowledge Graph? | IBM. (n.d.). Www.ibm.com. https://www.ibm.com/topics/knowledge-graph
- Yang, L., Chen, H., Li, Z., Ding, X., & Wu, X. (2023). Give Us the Facts: Enhancing Large Language Models with Knowledge Graphs for Fact-aware Language Modeling (Version 2). arXiv. https://doi.org/10.48550/ARXIV.2306.11489
- Feng, C., Zhang, X., & Fei, Z. (2023). Knowledge Solver: Teaching LLMs to Search for Domain Knowledge from Knowledge Graphs (Version 1). arXiv. https://doi.org/10.48550/ARXIV.2309.03118
-
Bosselut, A., Rashkin, H., Sap, M., Malaviya, C., Celikyilmaz, A., & Choi, Y. (2019). COMET: Commonsense Transformers for Automatic Knowledge Graph Construction (Version 2). arXiv. https://doi.org/10.48550/ARXIV.1906.05317Yu, S., Huang, T., Liu, M., & Wang, Z. (2023). BEAR: Revolutionizing Service Domain Knowledge Graph Construction with LLM. In Service-Oriented Computing (pp. 339–346). Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-48421-6_23Kommineni, V. K., König-Ries, B., & Samuel, S. (2024). From human experts to machines: An LLM supported approach to ontology and knowledge graph construction (Version 1). arXiv. https://doi.org/10.48550/ARXIV.2403.08345Hao, S., Tan, B., Tang, K., Ni, B., Shao, X., Zhang, H., Xing, E. P., & Hu, Z. (2022). BertNet: Harvesting Knowledge Graphs with Arbitrary Relations from Pretrained Language Models (Version 3). arXiv. https://doi.org/10.48550/ARXIV.2206.14268














 粤ICP备17114055号
粤ICP备17114055号
 支持私有云部署
支持私有云部署






