要构建高质量的知识图谱以支持RAG技术,首先需要理解RAG技术的基本原理和需求。RAG(检索增强生成)技术结合了检索和生成两种能力,使得生成的文本具有更高的多样性。这种技术通过将检索到的不同信息作为输入,为大模型LLM提供不同的上下文,从而产生多样化的输出。生成依赖LLM的推理和输出能力,但因为LLM本身的知识冻结的局限,输出内容的质量很大程度上就依赖检索能力提供的上下文,巧妇难为无米之炊。很长时间以来,工程师们一直在探索如何从海量的信息中检索出更符合用户需求的技术,这点做搜索引擎的公司应该有最多的积累。虽然LLM的崛起给了大家跟更多的选择,但是底层的检索技术积累还是能增强LLM的表现。Graph RAG是一种基于知识图谱的检索增强技术,通过构建图模型的知识表达,将实体和关系之间的联系以图的形式展示,从而提高了RAG系统的效率和效果。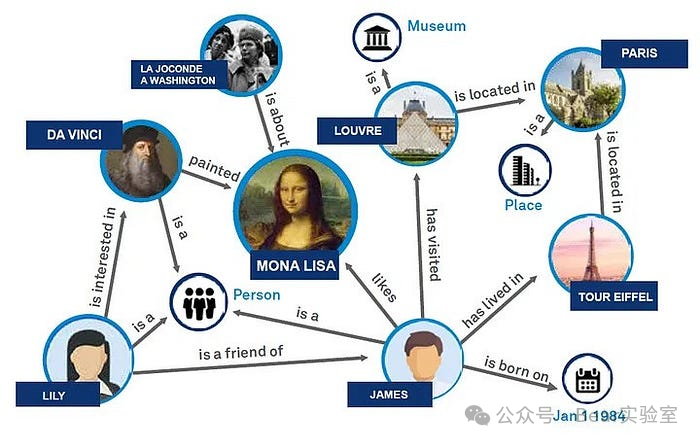
我们看看下面这个例子,通过 Graph RAG回答这些问题,因为 LLM 生成的知识图谱告诉LLM整个数据集的结构(以及主题)。这允许将私有数据集组织成预先汇总的有意义的语义集群。LLM在响应用户查询时使用这些集群来总结这些主题。
我们通过向两个系统提出以下问题来说明整个数据集的推理能力:
查询:“数据中排名前 5 的主题是什么?”

从基线 RAG 的结果来看,我们发现列出的主题都与两国之间的战争没有太大关系。正如预期的那样,向量搜索检索到了不相关的文本,并将其插入到法学硕士的上下文窗口中。包含的结果很可能以“主题”一词为关键,导致对数据集中发生的情况的评估不太有用。
观察 Graph RAG 的结果,我们可以清楚地看到结果与整个数据集中发生的情况更加一致。答案提供了五个主要主题以及数据集中观察到的支持细节。引用的报告由LLM为 Graph RAG 中的每个语义集群预先生成,并反过来提供原始源材料的出处。
Graph RAG利用图数据库作为上下文信息的来源,这不仅提高了信息的准确性,还增强了语言模型对实际文档中提取的文本块的理解能力,从而提高了整体的语义正确性和语言精确度。此外,Graph RAG在检索时能够将实体和关系作为单元进行联合建模,这种方法使得它能够更好地捕捉和利用知识图谱中的深层次结构和联系。
- 客服系统,领英LinkedIn落地RAG结合Graph来进行用户问答服务LLM应用,能够显著提升信息检索的质量和速度,提供更加准确和丰富的问答服务。
- 行业研究,Graph RAG能够通过分析大量文本数据,提供内容推荐、情感分析等功能,增强新闻编辑和发布的效率。可以参考这篇论文https://arxiv.org/abs/2404.16130,作者小哥使用Graph RAG索引和检索海量的文档数据源,生成更优的回答。
- 个人或企业知识库,例如通过检索某个领域的论文和博客,构建自己的知识体系,类似第二大脑的应用。
- 推荐系统,在电商、视频流媒体和在线教育等领域,Graph RAG可以通过分析用户行为和偏好,以及商品或课程之间的关系,来提供个性化的内容推荐。
Graph RAG是对RAG的一种优化方案,他们之间不是替代关系,同时引入Graph必然会带来技术复杂度和成本的提升。
我们以LangChain和Neo4j为例介绍如何实现基于Graph RAG的LLM应用,基础的流程主要分为两个阶段:索引和查询。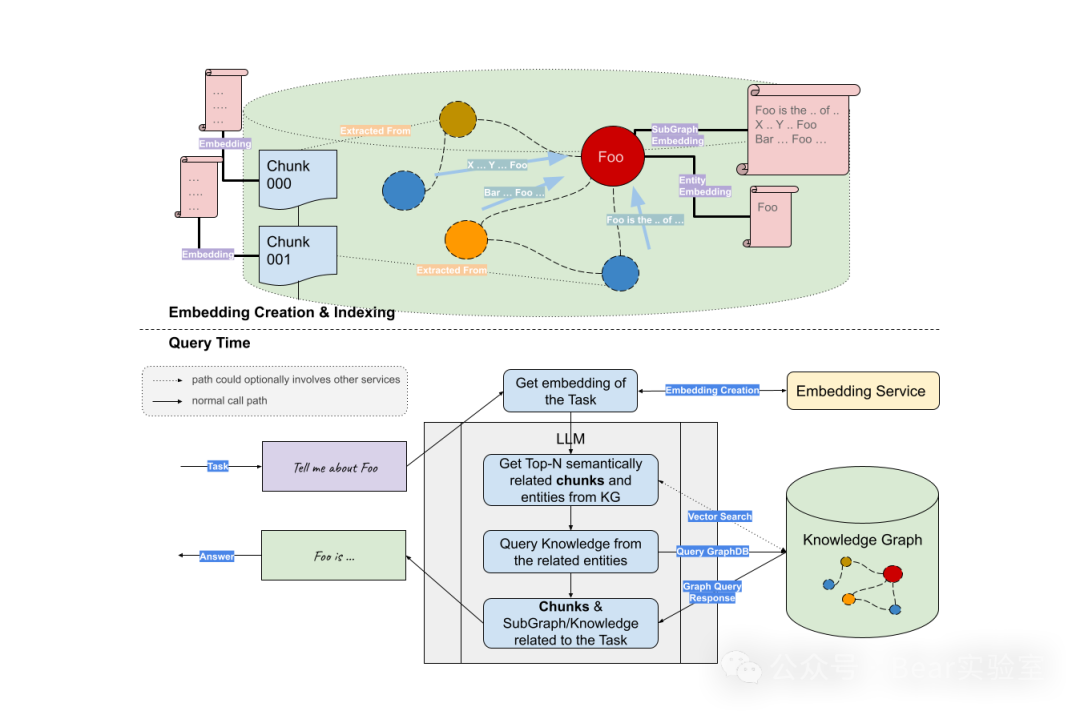
- 从文本中提取结构化信息:借助LLM从文本中抽取结构化图形信息。
- 存储到图形数据库中:将提取的结构化图形信息存储到图形库中,可实现下游RAG应用程序
from langchain_community.graphs import Neo4jGraphfrom langchain_experimental.graph_transformers import LLMGraphTransformer from langchain_openai import ChatOpenAIfrom langchain_core.documents import Document
graph = Neo4jGraph()llm = ChatOpenAI(temperature=0, model_name="gpt-4-0125-preview") llm_transformer = LLMGraphTransformer(llm=llm)
from langchain_core.documents import Document
text = """Marie Curie, was a Polish and naturalised-French physicist and chemist who conducted pioneering research on radioactivity.She was the first woman to win a Nobel Prize, the first person to win a Nobel Prize twice, and the only person to win a Nobel Prize in two scientific fields.Her husband, Pierre Curie, was a co-winner of her first Nobel Prize, making them the first-ever married couple to win the Nobel Prize and launching the Curie family legacy of five Nobel Prizes.She was, in 1906, the first woman to become a professor at the University of Paris."""documents = [Document(page_content=text)]graph_documents = llm_transformer.convert_to_graph_documents(documents)print(f"Nodes:{graph_documents[0].nodes}")print(f"Relationships:{graph_documents[0].relationships}")
graph.add_graph_documents(graph_documents)
从文本中提取图形数据可以将非结构化信息转换为结构化格式,有助于深入了解复杂的关系和模式,并提高检索效率。LLMGraphTransformer通过利用LLM来解析和分类实体及其关系,将文本文档转换为结构化图关系。请注意,由于我们使用的是LLM,因此图构建过程是不确定的,每次执行可能会得到略有不同的结果。
- 将问题转换为图数据库查询:LLM将用户输入转换为图查询语言(例如Cypher)。
- 执行查询:执行图数据库的查询,并返回查询到的数据。
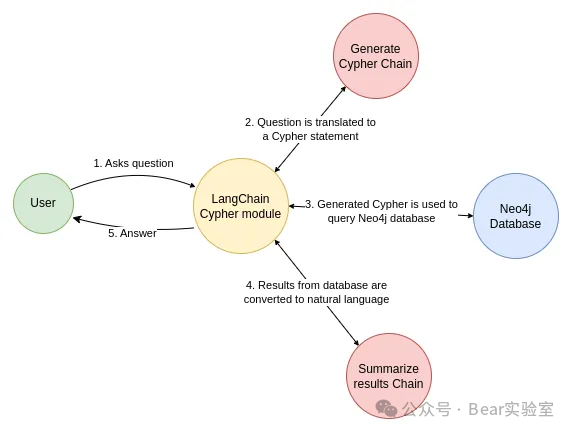
LangChain示例,创建一个与Neo4j数据库的连接,使用电影及其演员的示例数据。为了使LLM能够生成Cypher语句,需要有关数据库schema的信息。当实例化一个图对象时,它会检索schema相关信息。如果后续图数据结构有任何更改,则可以执行refresh_schema方法来刷新schema信息。
LangChain内置了一个机遇Neo4j实现的chain实现上面图例的工作流,它接受一个问题,将其转换为Cypher查询,执行查询,并使用结果来回答原始问题。
from langchain_community.graphs import Neo4jGraph from langchain.chains import GraphCypherQAChain from langchain_openai import ChatOpenAI graph = Neo4jGraph()llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0) chain = GraphCypherQAChain.from_llm(graph=graph, llm=llm, verbose=True) response = chain.invoke({"query": "What was the cast of the Casino?"})
print(response)
这只是一个基础的Graph RAG流程,为了得到更好的效果,我们还可以使用混合检索,图检索结合向量化、关键字。从用户提出问题开始的检索过程,然后将问题引导到RAG检索器。使用关键字和向量化来检索非结构化文本数据,并将其与从知识图谱中收集的信息相结合。由于Neo4j同时具有关键字索引和向量索引,因此可以使用单个数据库系统实现所有三种检索选项。从这些来源收集的数据被输入LLM,以生成并提供最终答案。
另一种基于MapReduce的方式,LLM 处理整个数据集,创建对源数据中所有实体和关系的引用,生成的知识图谱。然后,基于知识图谱创建自下而上的聚类,将数据按层次结构组织成语义聚类,这种划分允许对语义概念和主题进行预先总结,有助于对数据集的整体理解。在查询时,这两个结构都用于在回答问题时为 LLM 上下文窗口提供材料,使它能够回答不同抽象级别的问题。随着Graph RAG技术的持续演进,预计未来将在以下几个方向进一步发展:
- 多模态集成:探索将向量表示与知识图谱结合的Vector+Graph RAG,以及自我增强(Self-RAG)和多向量检索器的多模态RAG集成,以提高模型的理解能力和响应质量。
- 减少大模型的“幻觉”:通过改进检索增强技术,减少由大型语言模型产生的误导性或不准确的输出,即所谓的“幻觉”。这可以通过更精细的数据处理和更高效的信息检索机制来实现。
- 提升企业落地能力:Graph RAG旨在提升大型语言模型在实际应用中的企业落地能力,特别是在智能问答领域,通过提供更全面、更精准的上下文信息来优化搜索引擎和推荐系统。
总结来说,Graph RAG技术在提高搜索结果的精准度和减少大模型误导性输出方面具有潜力,但也不是银弹,回到非常具体实际业务场景,我们面对的问题都要比上面列举的示例复杂得多。本文介绍的内容希望能给大家提供一种思路,抛砖引玉~~
参考
https://github.com/langchain-ai/langchain/tree/master/templates/neo4j-advanced-raghttps://python.langchain.com/docs/use_cases/graph/quickstart/https://blog.langchain.dev/enhancing-rag-based-applications-accuracy-by-constructing-and-leveraging-knowledge-graphs/https://arxiv.org/abs/2404.16130






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
