引言
从GPT-4o、Claude 3.7到Llama-4,这些模型在海量数据上进行训练,展现出惊人的知识蒸馏和任务解决能力。然而,现有的模型往往面临一个核心挑战:如何在深度推理(需要多步思考)与快速响应(需要直接、上下文驱动的回答)之间取得平衡?用户常常需要在专门为聊天优化的模型和专注于推理的模型之间切换,这无疑增加了使用的复杂性。
为了解决这一痛点,并进一步提升开源大模型的整体性能和效率,阿里在近日发布了Qwen3系列模型。Qwen3不仅继承了Qwen系列在性能上的卓越传统,更在模型设计上进行了大胆创新,旨在实现思考模式与非思考模式的无缝融合。
本文结论抢先看:
- 开创性融合模式: Qwen3首次将“思考模式”(用于复杂多步推理)和“非思考模式”(用于快速上下文响应)集成到单一模型中,并引入“思考预算”机制,允许用户动态分配计算资源,实现性能与延迟的最佳平衡。
- 极致的预训练规模与多语言支持: 模型在高达36万亿Token的数据上进行预训练,数据量相比前代显著增加,支持119种语言和方言,极大地拓宽了全球应用场景。
- 高效与稳健的架构升级: 在模型架构上,Qwen3密集模型移除了QKV-bias并引入了QK-Norm以提高训练稳定性;MoE(专家混合)模型则通过移除共享专家并采用全局批次负载均衡损失,进一步提升了专家分工和推理效率。
- 全面领先的卓越性能: Qwen3系列模型在各项基准测试中均取得了领先的SOTA(State-of-the-Art)表现,尤其在代码生成、数学推理和Agent任务等领域,其旗舰模型Qwen3-235B-A22B甚至在多项指标上超越了DeepSeek-V3等顶尖开源模型,并与GPT-4o、Gemini2.5-Pro等闭源模型匹敌。
- “强到弱”蒸馏策略: 针对小型模型,Qwen3引入了创新的“强到弱”蒸馏策略,通过从大型旗舰模型中汲取知识,使得小模型在保持高竞争力的同时,大幅降低了训练成本和开发工作量。
接下来,我们将详细探讨这些令人兴奋的创新点。
模型架构揭秘:稳健与高效并存
Qwen3在模型架构上进行了迭代和优化,旨在实现更高的训练稳定性和推理效率。它包含了两类模型:密集模型(Dense Models)和专家混合模型(Mixture-of-Expert, MoE Models)。
密集模型(Dense Models)
Qwen3系列包含了6个密集模型,参数规模从0.6亿到320亿不等。这些模型在很大程度上沿用了Qwen2.5的优秀架构,例如:
- 分组查询注意力(Grouped Query Attention, GQA)
- 旋转位置嵌入(Rotary Positional Embeddings, RoPE)
然而,Qwen3并非简单地复制。论文中提到,研究团队移除了Qwen2中使用的QKV-bias,并引入了QK-Norm。这一改动非常关键:
- QKV-bias:在注意力机制中,QKV-bias指的是添加到查询(Query)、键(Key)、值(Value)向量上的偏置项。虽然它们能增加模型的表达能力,但在某些情况下可能会导致训练不稳定或性能下降。
- QK-Norm:是一种在查询和键之间应用的归一化技术,旨在确保注意力计算的稳定性。通过这一调整,Qwen3的密集模型在训练过程中能够更加稳健。
专家混合模型(MoE Models)
Qwen3系列还推出了两款MoE模型:Qwen3-30B-A3B和旗舰模型Qwen3-235B-A22B。MoE架构的特点是,模型包含多个“专家网络”,在推理时,只会激活其中一部分专家来处理输入,从而在参数量巨大的情况下,实现高效的推理。
Qwen3的MoE模型设计亮点包括:
- 128个专家,每个Token激活8个专家:这意味着模型拥有非常多的“专业领域知识”,但在处理每个输入时,只会调用其中8个最相关的“专家”,这极大地提高了推理效率。
- 移除了共享专家(Shared Experts):与Qwen2.5-MoE不同,Qwen3-MoE模型不再使用共享专家。
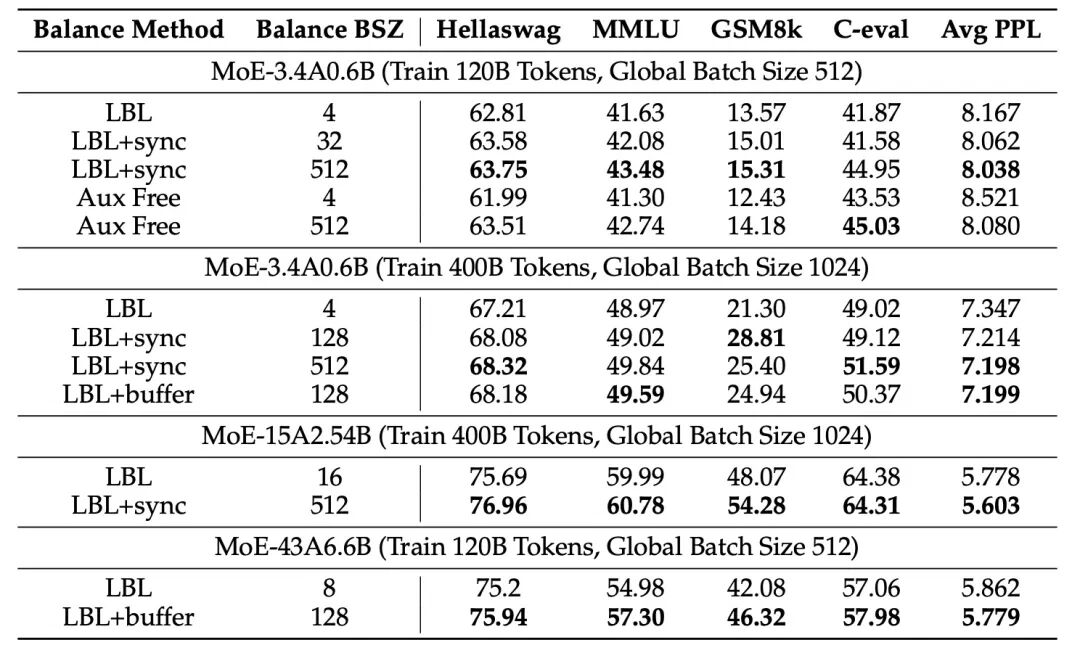
- 引入全局批次负载均衡损失(Global-batch Load Balancing Loss):这是MoE模型训练中的一项重要优化。
- 在传统的MoE训练中,负载均衡通常在微批次(micro-batch)维度进行,这可能导致专家在整个训练过程中无法充分利用数据多样性进行学习。
- 全局批次负载均衡则是在更大的全局批次维度上进行,这意味着模型在训练时能够从更广的数据分布中学习,促使专家们更好地进行专业化分工,避免少数专家承担过多任务而多数专家空闲的情况。这不仅提高了训练效率,也增强了模型的整体性能。如下图所示,全局负载均衡显著提高了下游任务的表现,并且提高了专家的专业化分工。
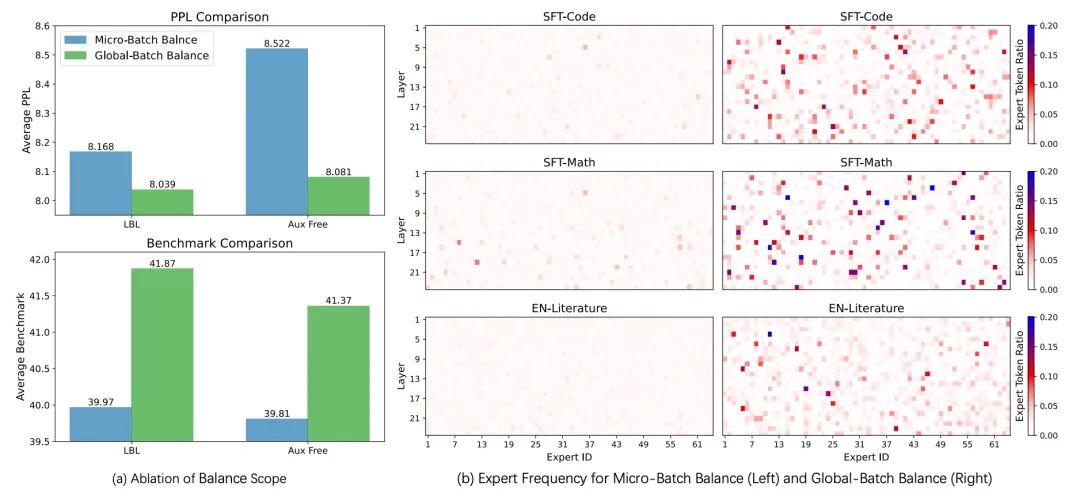
此外,Qwen3模型继续沿用了Qwen的tokenizer,词汇表大小为151,669。这些架构上的精妙设计,为Qwen3的卓越性能奠定了坚实基础。
海量数据铸就:Qwen3的预训练之路
Qwen3之所以能达到如此高的性能,与其在预训练阶段的海量数据规模和精细化处理密不可分。论文指出,Qwen3在预训练数据方面进行了大幅扩展,数据总量比Qwen2.5翻了一倍,支持的语言种类更是增加了两倍多。
数据规模与多样性
Qwen3的预训练数据集包含了惊人的36万亿(Trillion)Token,涵盖了119种语言和方言。这意味着模型在训练时接触到了前所未有的语言和知识广度。为了构建如此庞大且高质量的数据集,研究团队采取了多种策略:
- PDF文档文本提取与精炼: 利用Qwen2.5-VL(Qwen2.5视觉语言模型)从大量的PDF文档中提取文本,再通过Qwen2.5模型对识别出的文本进行精炼,有效获取了数万亿Token的高质量文本数据。
- 领域特定数据合成: 借助Qwen2.5、Qwen2.5-Math(数学模型)和Qwen2.5-Coder(代码模型)等专业模型,合成了数万亿Token的特定领域数据,包括教科书、问答对、指令和代码片段,覆盖数十个领域。这确保了模型在特定专业领域的深度学习。
- 多语言数据扩展: 进一步纳入了额外的多语言数据,使得支持的语言数量从Qwen2.5的29种大幅增加到119种,显著提升了模型的跨语言理解和生成能力。
- 细粒度数据标注与混合: 团队开发了一个多语言数据标注系统,对超过30万亿Token的数据在教育价值、领域、主题、安全性等多个维度进行了详细标注。与以往在数据源或领域层面进行混合优化不同,Qwen3的方法在实例(Instance)级别进行数据混合优化,通过在小型代理模型上进行大量的消融实验,实现了更有效的细粒度数据组合。
三阶段预训练策略
Qwen3的预训练过程采用了三阶段(Three-stage)策略,循序渐进地赋予模型强大的能力:
- 通用阶段(General Stage - S1): 在这一阶段,所有Qwen3模型首先在超过30万亿Token的数据上进行训练,序列长度为4,096 Token。目标是建立模型对119种语言的熟练掌握和广泛的通用世界知识基础。
- 推理阶段(Reasoning Stage - S2): 为了进一步提升模型的推理能力,这一阶段的预训练语料库重点增加了STEM(科学、技术、工程、数学)、代码、推理任务和合成数据的比例。模型在约5万亿高质量Token上进行训练,序列长度仍为4,096 Token,并在此阶段加速了学习率衰减,以更快地聚焦和强化推理能力。
- 长上下文阶段(Long Context Stage): 在最后的预训练阶段,研究团队收集了高质量的长上下文语料库,将Qwen3模型的上下文长度扩展到32,768 Token。这个语料库中,75%的文本长度在16,384到32,768 Token之间,25%在4,096到16,384 Token之间。与Qwen2.5类似,Qwen3将RoPE的基频从10,000提高到1,000,000,并引入了YARN(Yet Another RoPE Normalization)和双块注意力(Dual Chunk Attention, DCA)技术,以在推理时将序列长度容量提高四倍,从而实现对超长上下文的高效处理。
通过这三个阶段的精心设计,Qwen3模型不仅拥有了扎实的通用知识,还具备了卓越的推理能力和处理超长文本的优势。
预训练表现概览
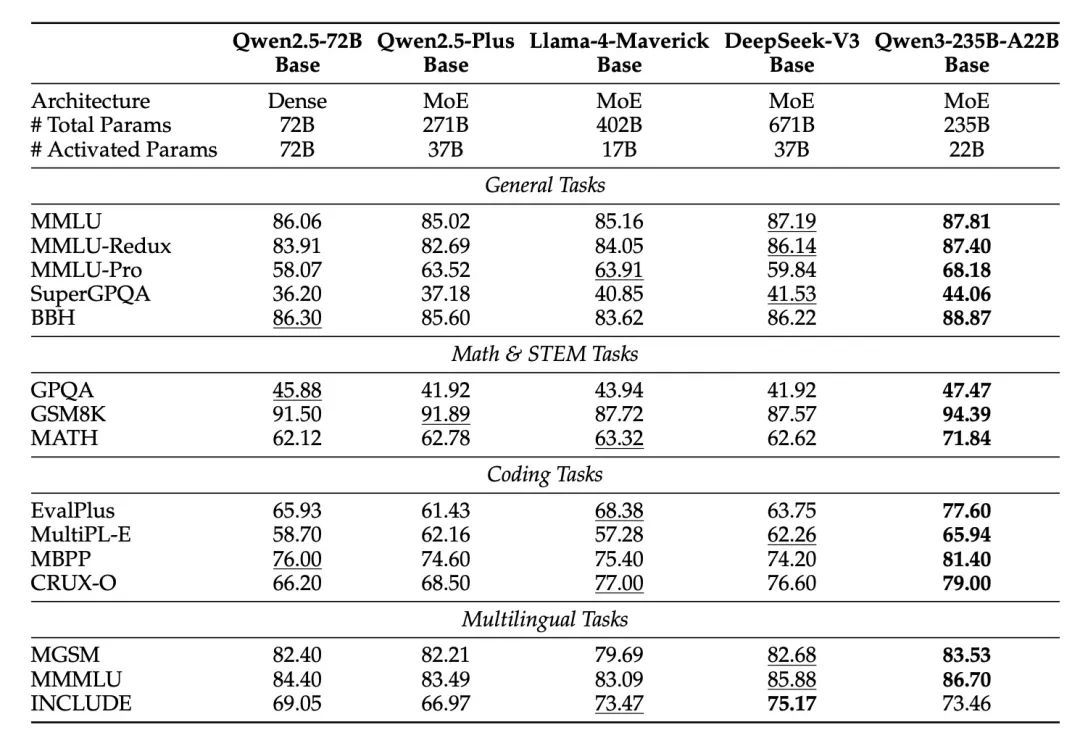
论文详细对比了Qwen3基础模型在通用任务、数学与STEM、代码以及多语言任务上的表现。核心亮点包括:
- 旗舰模型Qwen3-235B-A22B-Base的全面领先: 即使与DeepSeek-V3 Base(总参数是Qwen3的3倍,激活参数是1.5倍)和Llama-4-Maverick(总参数是Qwen3的2倍)等顶尖开源模型相比,Qwen3-235B-A22B-Base在绝大多数基准测试中都表现更优。与自家前代Qwen2.5-72B-Base相比,其在所有基准上均超越,且激活参数仅为其1/3,显著降低了推理和训练成本。
- MoE模型的惊人效率: Qwen3的MoE基础模型能够以仅1/5的激活参数达到与Qwen3密集模型相似的性能,并且在激活参数和总参数都少于Qwen2.5 MoE模型一半的情况下,表现更优。这意味着更高的性能效率比。
- 小模型的竞争力提升: Qwen3的密集模型,如Qwen3-32B-Base,在多项基准测试中甚至超越了Qwen2.5-72B-Base,尽管其参数量仅为后者的一半不到。这表明Qwen3在模型效率和能力上实现了跨越式提升,使得较小规模的模型也能拥有强大的竞争力。
这些预训练阶段的成果,为后续模型能够应对复杂指令和多变场景奠定了坚实的基础。
精雕细琢:Qwen3的后训练秘籍
预训练赋予模型通用知识和初步能力,而后训练(Post-training)则是将这些“原始能力”打磨成能够精准理解和响应用户指令的“利器”。Qwen3的后训练流程设计巧妙,具有两大核心目标:
- 思考控制(Thinking Control): 赋予模型在“思考”和“非思考”模式之间切换的能力,并能根据用户需求控制思考的深度(通过思考预算)。
- 强到弱蒸馏(Strong-to-Weak Distillation): 针对小型模型,通过从大型模型中学习,在显著降低计算成本和开发工作量的同时,大幅提升其性能。
Qwen3的旗舰模型(如235B-A22B)遵循一个复杂的四阶段训练过程,而小型模型则通过创新的蒸馏技术高效地获得了类似的能力。
四阶段后训练流程 (Four-Stage Post-training Process)
1. 长链思维冷启动(Long-CoT Cold Start)
这是模型学习生成长推理链(Chain-of-Thought, CoT)的起始阶段。团队精心构建了一个包含数学、代码、逻辑推理和STEM问题的综合数据集,每个问题都配有经过验证的参考答案或代码测试用例。
- 查询过滤(Query Filtering): 剔除难以验证的查询(如包含多个子问题或需要通用文本生成),以及Qwen2.5-72B-Instruct无需CoT就能正确回答的查询。这确保了模型只学习处理真正需要深度推理的复杂问题。
- 响应过滤(Response Filtering): 利用QwQ-32B(Qwen3系列中的一个推理模型)为每个查询生成多个候选响应。然后,对这些响应进行严格筛选,移除最终答案不正确、重复、纯猜测无推理、思考与总结不一致、语言混杂或风格偏移,以及与验证集过于相似的响应。
- 目标: 在这一阶段,目标是让模型形成基本的推理模式,而非立即追求推理性能的极致。通过最小化训练样本和步骤,为后续强化学习阶段的更大提升留出空间。
2. 推理强化学习(Reasoning RL)
在模型具备初步CoT能力后,进入推理强化学习阶段,进一步提升其推理能力。
- 数据选择原则: 选择在冷启动阶段未使用、冷启动模型可学习、足够具有挑战性且覆盖广泛子领域的数据。
- 训练策略: 采用GRPO(Gradient Regret Policy Optimization)策略,并发现使用大批次、高rollout次数和离线训练(Off-policy Training)对提升样本效率和训练过程非常有利。通过控制模型的熵(entropy),研究团队成功地平衡了探索和利用,实现了训练奖励和验证性能的持续提升。例如,Qwen3-235B-A22B模型在AIME'24上的分数从70.1提高到85.1。
3. 思考模式融合(Thinking Mode Fusion)
此阶段旨在将“非思考”能力融入到已具备“思考”能力的模型中,让一个模型能够同时处理这两种模式,降低部署多个模型的复杂性。
- SFT数据构建: 将“思考”数据(利用Stage 2模型进行拒绝采样生成)和“非思考”数据(包含代码、数学、指令遵循、多语言任务、创意写作、问答等多样化任务)结合起来进行持续的监督微调(SFT)。通过自动生成的检查清单和增加低资源语言的翻译任务,确保数据质量和多样性。
- 聊天模板设计: 为了实现模式的动态切换,Qwen3设计了独特的聊天模板。通过在用户查询或系统消息中引入
/think和/no_think标记,模型能够识别并根据指令选择相应的思考模式。默认情况下模型处于思考模式,如果用户未指定,模型会倾向于思考。在多轮对话中,模型会遵循遇到的最后一个标记。 - 思考预算的“涌现”能力: 一个令人惊喜的发现是,一旦模型学会了在两种模式下响应,它就自然而然地发展出了处理中间情况的能力——即基于不完整的思考来生成响应。当模型的思考长度达到用户定义的阈值时,系统会主动中断思考过程,并插入一条“考虑到用户时间有限,我将基于目前的思考直接给出解决方案”的指令,然后模型会根据已有的思考生成最终响应。这种能力并非明确训练,而是模型融合学习的自然结果。

4. 通用强化学习(General RL)
最终阶段旨在全面提升模型的各项能力和在不同场景下的稳定性。
- 全面奖励系统: 建立了涵盖20多个不同任务的复杂奖励系统,每个任务都有定制的评分标准,以增强模型的:
- 指令遵循能力: 准确理解和执行用户指令(内容、格式、长度、结构化输出)。
- 格式遵循能力: 严格遵循指定格式,如对
/think和/no_think标记的响应,以及使用<think>和</think>标记分隔思考和响应内容。 - 偏好对齐: 针对开放式查询,提升模型的帮助性、参与度和风格,提供更自然、更令人满意的用户体验。
- Agent能力: 训练模型通过指定接口正确调用工具,并通过与真实环境的交互反馈提升在长周期决策任务中的性能和稳定性。
- 专业场景能力: 例如在RAG(检索增强生成)任务中,引入奖励信号引导模型生成准确、上下文恰当的响应,减少幻觉。
- 基于规则的奖励: 适用于推理和格式遵循等任务,能高精度评估输出的正确性。
- 基于模型的带参考答案奖励: 针对每个查询提供参考答案,并利用Qwen2.5-72B-Instruct对模型的响应进行评分,灵活处理多样化任务。
- 基于模型的无参考答案奖励: 利用人类偏好数据训练奖励模型,对响应进行评分,处理更广泛的查询,提升模型的参与度和帮助性。
强到弱蒸馏(Strong-to-Weak Distillation)
为了优化轻量级模型的后训练过程,Qwen3引入了创新的强到弱蒸馏(Strong-to-Weak Distillation)管道,针对5个密集模型和1个MoE模型。
- 离线蒸馏(Off-policy Distillation): 在初始阶段,团队结合教师模型在
/think和/no_think模式下生成的输出来进行响应蒸馏。这帮助轻量级学生模型建立基本的推理能力和模式切换能力。 - 在线蒸馏(On-policy Distillation): 在此阶段,学生模型会生成在线序列进行微调。学生模型在
/think或/no_think模式下生成响应,然后通过将学生模型的Logits与教师模型(Qwen3-32B或Qwen3-235B-A22B)的Logits对齐,最小化KL散度来进行微调。
核心优势: 这种蒸馏方法在性能和训练效率上都表现出巨大优势。与传统的强化学习相比,它能够在仅约1/10的GPU小时内实现显著更好的性能,尤其在提升Pass@64(多尝试解决问题)指标上效果显著。这表明,从强大的教师模型中蒸馏知识,能更有效地引导学生模型学习,并扩展其探索空间和推理潜力。
全方位评估:Qwen3的卓越性能
Qwen3团队对模型的性能进行了全面而严格的评估,覆盖了预训练模型和指令微调模型。评估不仅采用了广泛认可的开放基准,还利用了团队内部精心构建的、针对特定能力(如长上下文、代码、Agent任务)的自动化数据集,确保了评估的全面性和公正性。
思维模式下的卓越表现
Qwen3在思考模式下的表现尤其引人注目,展现了其强大的推理能力:
- 旗舰模型Qwen3-235B-A22B: 在思考模式下,该模型在多数基准测试中超越了DeepSeek-R1,特别是在数学、Agent和编程等需要深度推理的任务上,表现出开源模型中的顶尖推理能力。它甚至与OpenAI-o1、Grok-3-Beta和Gemini2.5-Pro等闭源模型展开激烈竞争,极大地缩小了开源与闭源模型在推理能力上的差距。
- 旗舰密集模型Qwen3-32B: 在思考模式下,Qwen3-32B在多数基准上超越了之前的最强推理模型QwQ-32B,成为320亿参数规模下的新SOTA。它在对齐和多语言性能方面也与闭源的OpenAI-o3-mini竞争。
非思维模式下的通用能力
即使在非思考模式下,Qwen3模型的通用能力也表现出色:
- Qwen3-235B-A22B: 在非思考模式下,它超越了DeepSeek-V3、LLaMA-4-Maverick以及自家的前代旗舰模型Qwen2.5-72B-Instruct。更令人印象深刻的是,它在多项基准测试中甚至超越了GPT-4o-2024-11-20,这表明其即使不启动复杂的思考过程,也拥有强大的固有能力。
- Qwen3-32B: 在非思考模式下,该模型在几乎所有基准测试中都表现优异,甚至在对齐、多语言和推理相关任务上,显著超越了Qwen2.5-72B-Instruct,证明了Qwen3系列在基础能力上的全面提升。
- 轻量级模型: 包括Qwen3-30B-A3B、Qwen3-14B以及其他更小规模的密集模型,在参数量相近或更小的情况下,其性能持续优于同类开源模型,这充分验证了“强到弱”蒸馏策略的成功,使得轻量级模型也能具备强大的竞争力。
多语言能力
Qwen3在预训练阶段支持119种语言,其多语言能力也在评估中得到了充分体现。团队扩展了多个多语言基准测试,覆盖了指令遵循、知识理解、数学和逻辑推理等多种任务。Qwen3在多语言任务上取得了显著进展,尤其在一些低资源语言上也表现出强大的理解和生成能力。
长上下文处理能力
Qwen3模型在处理长上下文方面的能力也经过了严格测试:
- RULER、LV-Eval和LongBench-Chat: 在这些长上下文基准测试中,Qwen3系列模型,特别是装备了YARN和DCA技术的模型,展现了强大的长文本处理能力。Qwen2.5-72B-Instruct在所有上下文长度上都表现出色,显著优于现有开源和如GPT-4o-mini、GPT-4等闭源模型。
- 1M Token Passkey Retrieval: Qwen2.5-Turbo在100万Token的Passkey Retrieval任务中取得了100%的准确率,这展示了其从超长上下文中提取细节信息的卓越能力。
- 推理速度优化: 通过基于Minference的稀疏注意力机制,Qwen2.5-Turbo在处理1M Token序列时,将注意力机制的计算负载降低了12.5倍,TTFT(Time To First Token)提速3.2到4.3倍,极大地提升了长上下文推理的用户体验。
思考预算的有效性
论文还通过实验验证了“思考预算”的有效性。在数学、代码和STEM领域的基准测试中,Qwen3的性能随着分配给思考的预算增加而持续且平稳地提高,这表明模型确实能够通过更“深入”的思考来提升解决问题的能力。
这些全面的评估结果,无疑证明了Qwen3在当前开源大模型领域中的领先地位,以及其在多功能性、效率和可扩展性方面的巨大潜力。
总结
阿里巴巴推出的Qwen3系列模型无疑是开源大模型领域的一个里程碑。它不仅延续了Qwen家族在性能上的卓越表现,更通过一系列开创性的技术创新,重新定义了我们对大模型能力边界的认知。
Qwen3的核心亮点在于其独创的思考模式与非思考模式融合机制,辅以精密的思考预算控制。这一设计使得模型能够灵活地在深度推理和快速响应之间切换,有效解决了不同任务对模型效率和智能水平的差异化需求,为用户提供了前所未有的灵活性。
在技术深层,Qwen3的架构升级(如密集模型的QK-Norm和MoE模型的全局批次负载均衡损失)确保了模型训练的稳健性和推理的极致效率。而36万亿Token的庞大数据量以及119种语言的广泛覆盖,则为Qwen3赋予了卓越的通用知识和全球化能力。
更令人称道的是,Qwen3通过精妙的四阶段后训练流程,尤其是“强到弱”蒸馏策略,不仅大幅提升了旗舰模型的综合实力,使其在各项基准测试中表现卓越,能与顶级闭源模型匹敌,还使得轻量级模型也能以极低的成本获得强大的性能,为边缘设备和资源受限环境下的AI应用打开了新的可能。






























 粤ICP备14082021号
粤ICP备14082021号
 免费POC,
零成本试错
免费POC,
零成本试错
