推荐语
大模型技术的最新应用实例,langchain框架的详细介绍及实际应用案例。
核心内容:
1. 大模型技术概述及其在各领域的广泛应用
2. 大模型与传统AI模型的区别及技术特点
3. langchain框架的功能和应用实例展示
杨芳贤
53AI创始人/腾讯云(TVP)最具价值专家
一、概述
大模型是最近一段时间以来最热门的技术了。过年期间我写了一篇《使用Ollama搭建自己的简单知识库》,点击率颇高,说明大家对大模型方面的知识还是比较关注的。特别是过年期间DeepSeek横空出世,直接打开了AI进入普通人工作生活的序幕,现在似乎大家已经越来越离不开AI了。
大模型现在有很多,国内也有很多可用的,并且效果非常好,如:DeepSeek,豆包,Kimi,通义千问,文心一言等等。可以取代传统的搜索引擎功能,并且可以生成文字、图像、视频等等,借助于工具甚至可以实现PPT自动制作,数据分析,智能人生成等等。不过我们技术人员,不光光要会用,还要知道一下大模型的原理,以及对其做一些扩展。今天我就简单介绍一下通过langchain来实现大模型的访问。
二、大模型
大模型属于Foundation Model(基础模型),是一种神经网络模型,具有参数量大、训练数据量大、计算能力要求高、泛化能力强、应用广泛等特点。与传统人工智能模型相比,大模型在参数规模上涵盖十亿级、百亿级、千亿级等,远远超过传统模型百万级、千万级的参数规模。不同于传统人工智能模型通过一定量的标注数据进行训练,一个性能良好的大模型通过海量数据及设计良好、内容多样的高质量标注语料库进行训练。同时,大模型也很难在单个GPU(GraphicsProcessing Unit,图形处理器)上进行预训练,需要使用DeepSpeed、Megatron-LM等训练优化技术在集群中进行分布式训练。其核心思想是通过大规模的无监督训练学习自然语言的模式和结构,在一定程度上模拟人类的语言认知和生成过程。
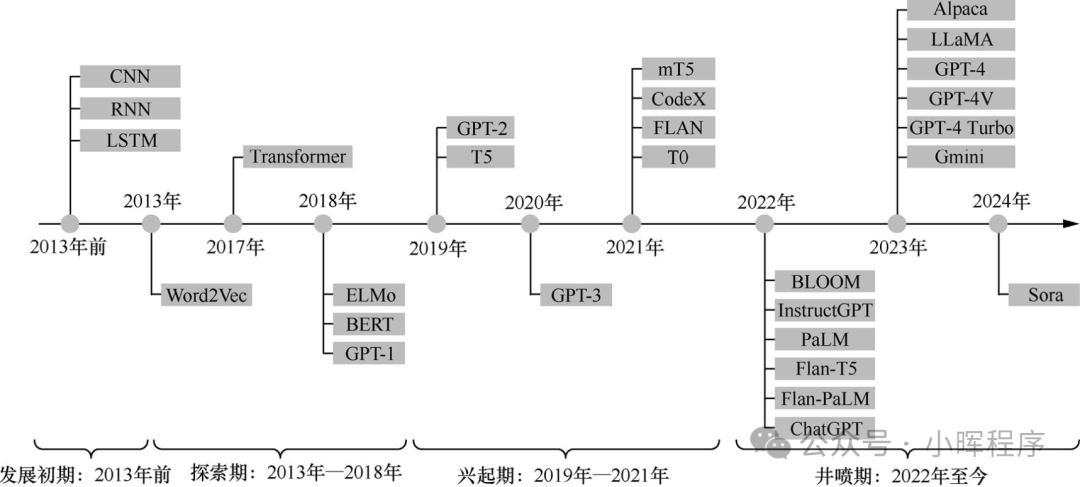
大模型的典型代表包括 GPT 系列(如 GPT-4)、PaLM、LLaMA、BERT、Stable Diffusion、MidJourney 等,覆盖自然语言处理(NLP)、计算机视觉(CV)及多模态(文本 + 图像 / 语音等)领域。目前在教育、医疗、金融、电商与零售、科研与工程等都有广泛的应用。下图是大模型技术的发展历程:
三、通过langchain访问大模型
langchain 是一个开源的 LLM 应用开发框架,专注于解决 “如何将大语言模型(如 GPT-4、LLaMA、Claude 等)与外部资源(数据、工具、API)结合,构建复杂交互式应用” 的问题。它通过模块化设计,让开发者无需从头实现底层逻辑,快速搭建具有 记忆能力、工具调用、多步推理 的智能应用。
langchain可以标准化提示词的构建流程,支持动态填充变量、模板化设计,提升大模型的输出质量,还允许大模型调用外部工具获取实时数据或执行操作,弥补自身知识局限。langchain可以定义多个步骤的固定流程,适用于结构化任务。也可以支持增强检索生成(RAG)和Agent(智能体)开发。
下面我用三个简单的例子说明一下langchain的使用。
1.直接访问大模型获得结果
使用langchain直接访问大模型,设置提示词,得到返回结果。
注:我在本地部署了Ollama框架,并在其上部署了deepseek-r1:7b和deepseek-r1:32b以及qwen模型。
from langchain_ollama.chat_models import ChatOllamafrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.output_parsers import StrOutputParseroutput_parser = StrOutputParser()# 设置大模型llm = ChatOllama(model="deepseek-r1:7b", temperature=0.1)# 设置提示词prompt = ChatPromptTemplate.from_messages([ ("system", "You are world class technical documentation writer."), ("user", "{input}")])# 构建工作链chain = prompt | llm | output_parser# 调用print(chain.invoke({"input": "What is the capital of France?"}))返回的结果如下:
<think>Okay, so I need to figure out what the capital of France is. Hmm, I remember learning a bit about countries and their capitals in school, but let me try to recall more accurately.... ...</think>The capital of France is Paris. It is renowned for its iconic landmarks such as the Eiffel Tower, Louvre Museum, and Notre-Dame Cathedral. Paris also houses significant government institutions like the Elysée Palace where the President resides, and it is a hub for international events and meetings.
由于deepseek-r1是推理模型,所以它的返回是带有推理过程的,由<think></think>包裹。
2.使用langchain结合web查询数据获取大模型返回结果
langchain不光可以直接访问大模型,还可以从web获取最新的知识,并和用户问题一起构建成完整的提示词,输入到大模型,从而得到更准确的返回结果。我们在DeepSeek等大模型界面里面看到的“联网搜索”,做的事其实就是类似的。
from langchain_ollama.chat_models import ChatOllamafrom langchain_core.prompts import ChatPromptTemplatefrom langchain_core.output_parsers import StrOutputParserfrom langchain.chains.combine_documents import create_stuff_documents_chainoutput_parser = StrOutputParser()llm = ChatOllama(model="qwen", temperature=0.1)prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:<context>{context}</context>Question: {input}""")document_chain = create_stuff_documents_chain(llm, prompt)################# 从网页中获取文档内容from langchain_community.document_loaders import WebBaseLoaderloader = WebBaseLoader("https://zrzy.jiangsu.gov.cn/xwzx/sbyq/2025/02/05151523141440.html")docs = loader.load()print( document_chain.invoke({ "input": "古树名木保护条例规定了哪些内容?", "context": docs }))这次我使用的本地的qwen大模型,该模型不是推理模型,所以没有推理过程。我首先从网站上获取新闻信息,然后把web上的新闻内容作为大模型上下文,跟用户问题拼接成完整的提示词,通过工作链提交给大模型,让它返回我需要的内容,返回结果如下:
《古树名木保护条例》共30条,主要规定了以下内容:1. 总体要求:规定古树名木保护管理工作坚持中国共产党的领导,坚持保护第一、合理利用、分级管理的原则,构建政府主导、属地负责、社会参与的工作机制。2. 分级分类认定公布:科学界定和划分古树名木的保护等级,明确古树名木普查、认定、公布程序,规定县级以上地方人民政府古树名木主管部门根据调查结果认定古树名木,报本级人民政府批准后依法公布。3. 加强日常养护管理:规定县级人民政府古树名木主管部门应当按照有利于加强古树名木日常养护的原则,明确有关单位、个人作为古树名木的日常养护责任人;日常养护责任人应当严格履行养护义务,制止损害古树名木及其生长环境的行为;对在古树名木保护管理工作中作出突出贡献的单位、个人,按照国家有关规定给予表彰和奖励。4. 严格限制采伐和移植:规定除抢险救灾等特殊紧急情形外,禁止采伐古树名木;依法采取应急处置措施采伐古树名木的,应当及时报告。规定古树名木原则上实行原地保护,不得移植;对于国家级、省级重点建设项目等选址确实无法避让古树名木,以及古树名木的生长状况可能危害公众生命安全,确需移植的,规定了严格的审批程序。5. 强化保障监督:将古树名木保护管理情况纳入领导干部自然资源资产离任审计;对古树名木保护管理工作不力、问题突出的地区,规定了约谈制度。
3.langchain加载本地文件内容获取大模型返回结果
langchain不光可以访问web,还可以结合本地文件内容访问大模型。我们可以读取本地的文件,作为上下文,构建出提示词,通过langchain来访问大模型,得到我们需要的返回结果。
from langchain_core.prompts import ChatPromptTemplatefrom langchain.chains.combine_documents import create_stuff_documents_chainfrom langchain_ollama.chat_models import ChatOllamafrom langchain_core.documents import Document# 本地DeepSeek-r1:32b大模型llm = ChatOllama( model="deepseek-r1:32b", temperature=0, # other params...)prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:<context>{context}</context>Question: {input},用中文回答""")document_chain = create_stuff_documents_chain(llm, prompt)content = ""try: with open('example.txt', 'r', encoding='utf-8') as file: # 读取文件的全部内容 content = file.read()except FileNotFoundError: print("文件未找到,请检查文件路径和文件名。")from langchain_openai import ChatOpenAIfrom langchain_core.output_parsers import StrOutputParserfrom langchain.schema.runnable import RunnableLambda, RunnablePassthroughfrom langchain.prompts import PromptTemplate# 在线DeepSeek API(满血版)model = ChatOpenAI( model='deepseek-chat', openai_api_key='<你的API KEY>', openai_api_base='https://api.deepseek.com', max_tokens=1024)prompt_template2 = "你是一名文档处理专家,精通阅读理解和文字编写,具有很高的审美水平和文字总结能力。有如下的文章{content},请帮我总结摘要。"PROMPT = PromptTemplate( template=prompt_template2, input_variables=["content"])# 在线版chain = ( {"content": RunnablePassthrough()} | PROMPT | model | StrOutputParser() )# 本地版#chain = (# {"content": RunnablePassthrough()}# | PROMPT# | llm# | StrOutputParser() #)input_data = { "content": content}# 使用 invoke 方法调用链result = chain.invoke(input_data)print(result)这里我提供了两种方法,一种是调用本地的deepseek-r1大模型(7b和32b),一种是访问在线的deepseek满血版API。在线版的性能更强大,得到的结果也更好。我这里在example.txt中放入了小说《盗墓笔记1七星鲁王宫》的第二章,让大模型帮我总结一下摘要。输出如下:
使用本地deepseek-r1:7b
<think>好的,我现在需要帮用户总结一个比较长的文档内容。首先,我得通读整个文档,了解整体情节和关键点。文档讲的是一个盗墓贼三叔的故事,他从古玩市场转行做盗墓,后来因为年龄大了,决定退休,但又忍不住出来倒手。过程中涉及到一些暗语、交易细节以及人物关系。用户希望我将这段内容进行摘要,所以我要抓住主要情节和人物发展。首先,故事的主角是三叔,他在盗墓行业有多年的经验,现在开始慢慢退休,但依然活跃在古玩市场。接着,他收到了一条短信,里面提到有新货到杭州,还有一条关于龙脊背的好东西。三叔对此很感兴趣,并决定去查看情况。在到达现场时,遇到了一些问题,比如被交警拦下,导致晚点,这可能影响了他的计划。然后,他发现年轻人背着一个樟木盒子,里面可能是宝剑或龙脊背的藏品。三叔确认后,觉得这是好东西,但因为时间关系,决定让年轻人帮忙收钱。之后,三叔提到有金牙老头,可能涉及倒卖文物的事情,还有一张地图,暗示了藏品的位置或其他重要信息。整个过程中,人物之间的互动和暗语是关键点,需要在摘要中体现出来。接下来,我需要将这些要点浓缩成一个简洁的摘要,确保涵盖主要情节、人物发展以及关键事件,同时保持逻辑连贯。</think>故事讲述了一位盗墓贼三叔从古玩市场转向盗墓行业,并逐渐退休但仍活跃于古玩市场的经历。三叔在一次交易中接到了两条短信,一条提到杭州有新货到货,另一条则指出有一件价值非凡的龙脊背藏品。他决定前往查看情况,但在途中被交警拦下,导致晚点。随后,他在年轻人的樟木盒中发现可能含有龙脊背的宝剑或刀具,并确认了藏品的真实性。三叔对藏品表现出浓厚兴趣,但因时间关系未能及时收货。与此同时,他提到有“北京来的金牙”涉及文物倒卖事件,并指出藏品可能与山西某墓有关。三叔还表示年轻人可能平时接受过他的教导,对此感到不满。最终,三叔决定让年轻人帮忙收钱,并对藏品的背景和位置表现出兴趣。整个故事通过暗语和人物互动展现了三叔在古玩市场的活跃以及他逐渐退休后但仍活跃于盗墓行业的复杂性。
使用deepseek-r1:32b
<think>好的,我现在需要帮用户总结一个文档的摘要。首先,我得仔细阅读用户提供的文本内容,理解其中的主要情节和关键点。看起来这个故事主要围绕盗墓和古玩交易展开,涉及多个角色,比如“我”、三叔、金牙老头等。故事开始于“我”在店里遇到一位金牙老人,他可能是在刺探情报。接着,“我”收到三叔的短信,提到有新货到,特别是提到了“龙脊背”,这似乎是指有价值的宝物。然后,“我”赶往三叔那里,但因为交通问题迟到了,结果好东西已经被卖掉。不过,三叔让“我”帮忙收钱,并且在喝酒时聊起了金牙老人的事情。三叔提到北京的金牙和摸金贼最近在山西有动作,可能与帛书有关。最后,“我”打印了数码相机里的帛书给三叔看,三叔回应说这是一张地图,暗示背后可能隐藏着更大的秘密或危险。总结时,我需要抓住这些关键点:盗墓、古玩交易、角色之间的联系、神秘的帛书以及潜在的危险。同时,要保持摘要简洁明了,突出故事的主要情节和转折点。</think>这段文字描述了一个与盗墓、古玩交易相关的故事片段,主要围绕主人公“我”和三叔的活动展开。以下是主要内容的总结:1. **金牙老头的刺探**:一位北京来的金牙老人来到店里,试图刺探情报,可能与近期山西某宝穴被盗有关。2. **三叔回忆与线索**:三叔提到近年来有嚣张的摸金贼活动,尤其是北京的金牙销货频繁,暗示近期山西墓葬可能被倒出大量宝贝。3. **帛书地图的发现**:“我”将数码相机中拍到的帛书打印出来给三叔看,三叔回应这是一张地图,并指出“我”平时不认真学习古玩知识。4. **潜在危险与秘密**:三叔对帛书表现出异常关注,暗示这张地图可能隐藏着重大秘密或危险。整个故事充满了盗墓、古玩交易的神秘色彩,同时揭示了主人公所处环境的复杂性和潜在风险。
使用deepseek满血版web api
**摘要:** 主人公在河坊街西泠社的古玩店中遇到一位神秘的金牙老头,对方以老痒(一个已入狱的熟人)的名义前来打听战国帛书拓本。金牙老头声称自己手上有相关线索,但主人公怀疑其动机,敷衍应对。交谈中,金牙老头透露对主人公爷爷(长沙著名盗墓贼“狗王”)的过去有所了解,并试图获取帛书信息,但主人公警觉地将其赶走,仅留下一份帛书复印件。 事后,主人公发现复印件上有一个诡异的狐狸人脸图案,意识到其价值,拍照留存。通过回忆,他简述了爷爷作为南派盗墓贼(土夫子)的背景,以及南北派盗墓的差异。当晚,主人公收到三叔(家族中仍在从事盗墓的成员)的短信,称有珍贵文物“龙 脊背”到货,但等他赶到时已被他人买走。交谈中,主人公提及金牙老头之事,三叔认出对方可能是北京著名的盗墓销赃人,并发现帛书复印件实为一张隐秘的地图,暗示其中可能隐藏重大秘密。 **核心要点:** 1. **神秘访客**:金牙老头以老痒为引,试探主人公家族与战国帛书的关联,意图不明。 2. **家族背景**:主人公爷爷是长沙南派盗墓传奇人物“狗王”,曾盗取战国帛书但被美国人骗走。 3. **帛书线索**:金牙留下的复印件暗藏玄机,后被三叔解读为一张地图,可能指向古墓或宝藏。 4. **三叔的提示**:三叔暗示金牙老头背后涉及北京盗墓团伙,帛书或与山西新盗墓穴有关。 5. **南北派之争**:插叙盗墓行业的南北派系分歧及爷爷的江湖地位,为故事增添历史纵深。 **悬念铺垫:** 帛书地图的真相、金牙老头的真实目的、三叔与盗墓团伙的潜在冲突,为后续剧情发展埋下伏笔。
有没有发现一个比一个更厉害,deepseek-r1:7b只看到了三叔的事情,没有提到金牙的事情,deepseek-r1:32b,主体内容已经比较正确了,deepseek满血版web api把主要内容摘要以及核心要点和悬念铺垫全部都归纳出来了,明显是效果最好的。
四、总结
可以看到,我们通过langchain可以访问本地大模型以及远程大模型的API,同时还可以结合web数据和本地数据构建完整提示词输入给大模型,以得到更好的回答效果。
































 粤ICP备14082021号
粤ICP备14082021号