





























 粤ICP备14082021号
粤ICP备14082021号
微信扫码
添加专属顾问
 免费POC,
零成本试错
免费POC,
零成本试错
我要投稿
微信搜一搜,关注“EosphorosAI”
DB-GPT V0.8.1 让AI数据助理从一次性分析工具升级为可重复、可连接、可观测的团队生产力核心。核心内容:1. 定时任务功能:将成功分析沉淀为周期任务,实现自动化报告与复盘2. MCP连接器:安全接入外部工具,扩展Agent能力边界3. 上下文管理与任务追踪:保障多步分析稳定执行,过程全透明
V0.8.1 把 AI数据助理 的能力进一步沉淀为可调度、可连接、可观察、可运维的生产化工作流,回答几个更偏生产化的问题:
围绕这些问题,本版本引入了定时任务、MCP 连接器、上下文管理与任务计划追踪,同时扩展模型、数据源、向量存储和缓存生态,并补充一批面向生产环境的性能、安全与兼容性修复。
V0.8.1 的核心价值可以概括为:让 AI 数据助理从“能完成一次复杂分析”,进一步走向“能被团队反复使用、持续运行和稳定运维”。
很多数据分析工作天然是周期性的:每日经营日报、每周风险检查、月度财务摘要,或基于最新数据库快照反复执行的诊断分析。V0.8.1 引入定时任务(Scheduled Tasks),让一次成功的分析对话可以沉淀为可重复执行的任务。
将对话保存为周期性任务一键保存已完成对话一键保存已完成对话:将任意完成的分析对话转化为定时任务。
灵活设置调度周期:支持每小时、每天、每周、每月,或自定义 Cron 表达式。
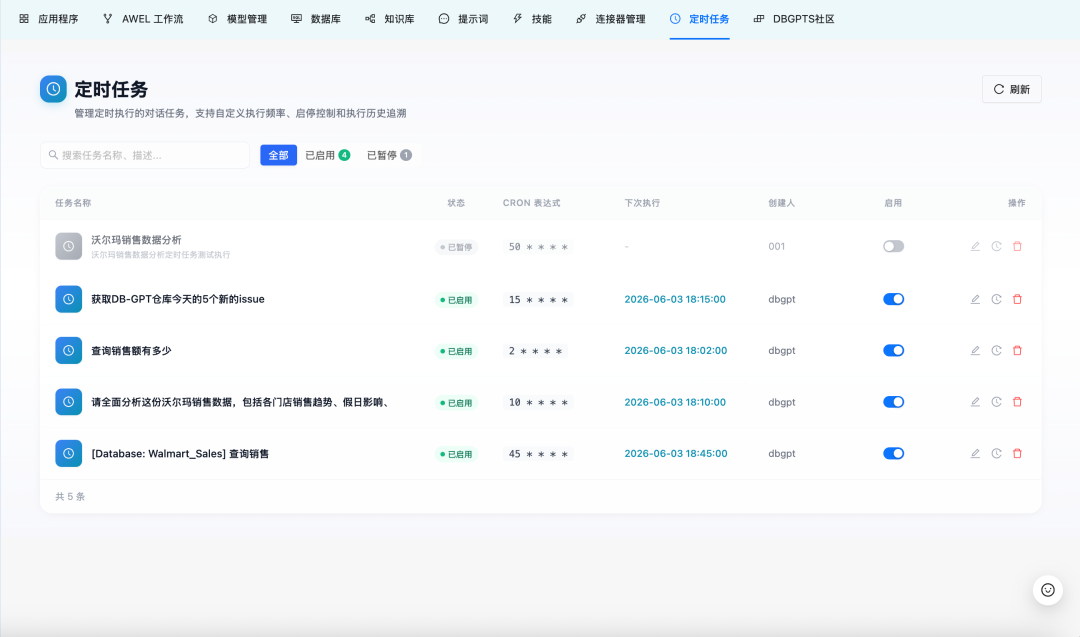
运行历史与只读回放每一次定时运行都会记录状态、耗时、结果摘要,以及它生成的对话 ID。你可以打开任意一次历史运行,直接从历史记录中回放该次对话;回放不会再次触发 LLM 调用,让复盘既低成本又可复现。
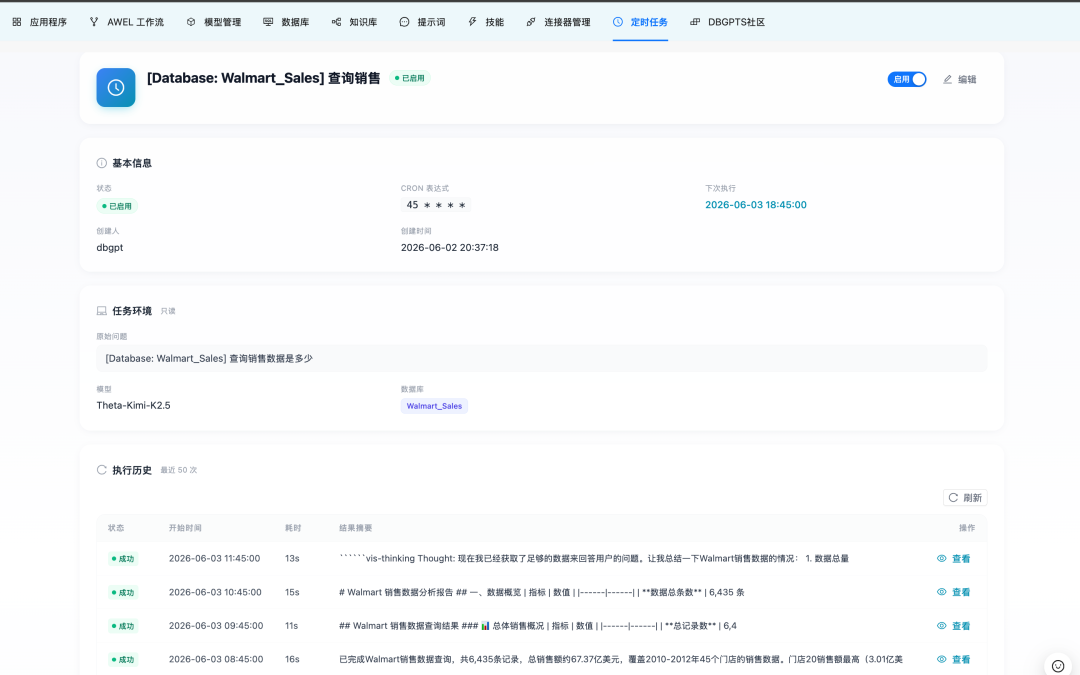
 🔌 MCP 连接器:让 Agent 安全接入外部工具
🔌 MCP 连接器:让 Agent 安全接入外部工具
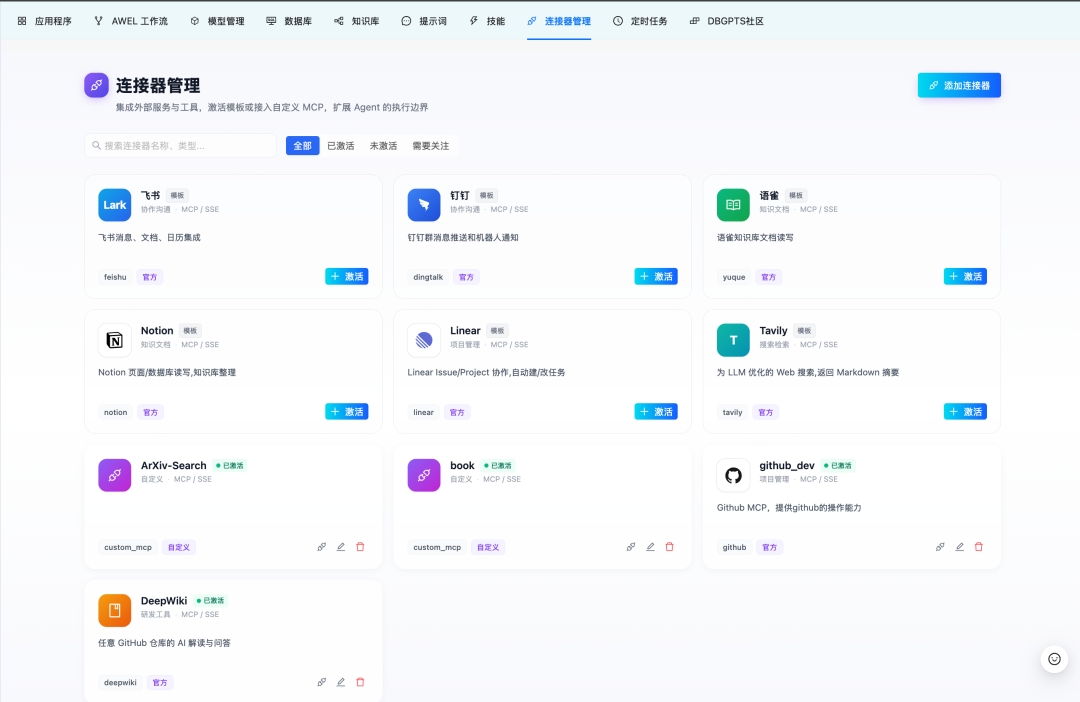
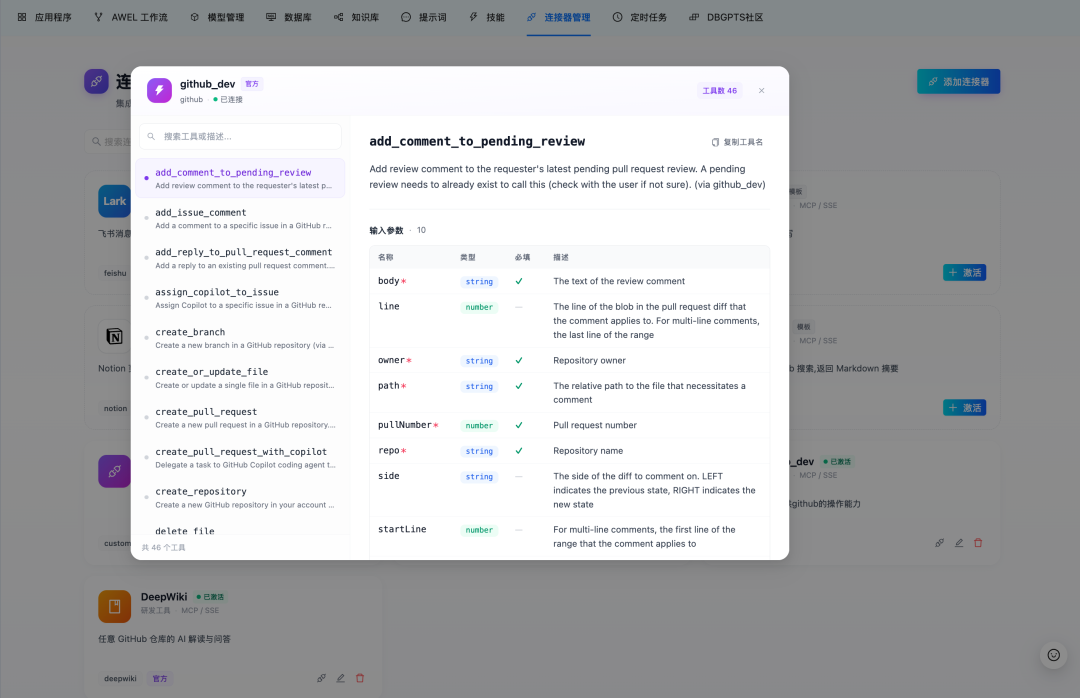
V0.8.1 通过 MCP 连接器(MCP Connectors) 将 DB-GPT Agent 的能力从数据库和本地 Skill 扩展到外部服务。Agent 现在可以通过 MCP 接入外部工具,同时由用户掌控每次会话到底挂载哪些连接器。
当前内置连接器模板包括飞书、钉钉、语雀、GitHub、Notion、Linear、Tavily 和 DeepWiki。你也可以接入任意支持 SSE 或 Streamable HTTP 的自定义 MCP Server。
 🧠 上下文管理与任务计划追踪:让长程任务更稳定、更透明
🧠 上下文管理与任务计划追踪:让长程任务更稳定、更透明
Agentic 数据分析往往不是一个短对话,而是需要多步探索、反复尝试、生成中间产物的长任务。V0.8.1 为 Data Agent 流程新增上下文管理与任务计划追踪,让长任务更稳定,执行过程也更易理解。
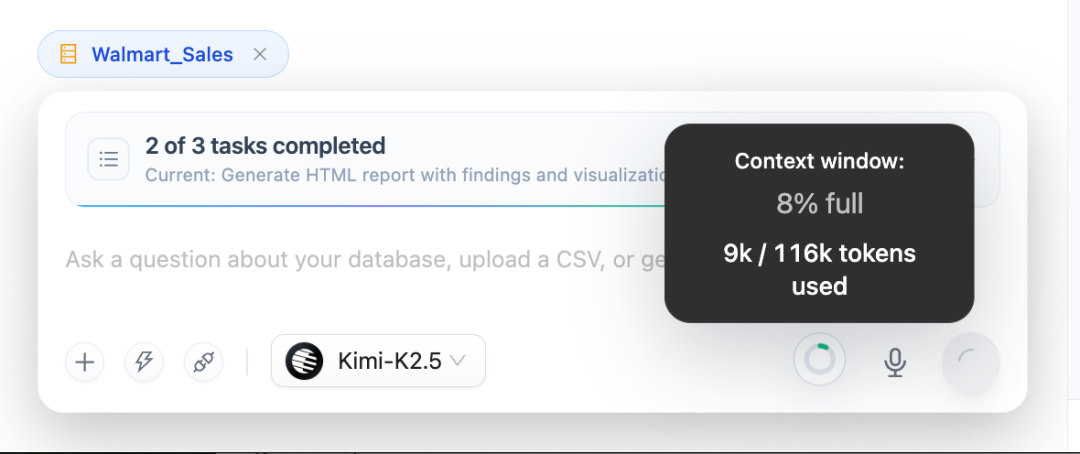
- 多层上下文压缩:帮助长任务避免超过模型上下文窗口。
- 实时上下文使用事件:将上下文窗口使用情况实时推送到前端。
- 任务计划追踪:Agent 维护结构化 Todo 列表,并在步骤推进时推送计划更新。
- 更清晰的动作解释:每一步动作都会展示它在做什么,以及为什么需要执行。
- 前端任务计划卡片与上下文使用指示器:让整个执行过程透明可见。
在底层,ContextManager 编排一套由 Token 预算状态驱动的渐进式多层压缩机制。随着用量越过警告与错误阈值,压缩力度逐级增强:从截断早期 Observation,到丢弃早期轮次,再到由LLM 生成结构化摘要;若模型仍报 context_too_long,还有应急兜底层。
这些改进让 DB-GPT 更适合承接需要多步推理、反复尝试和中间产物管理的复杂数据分析工作流。
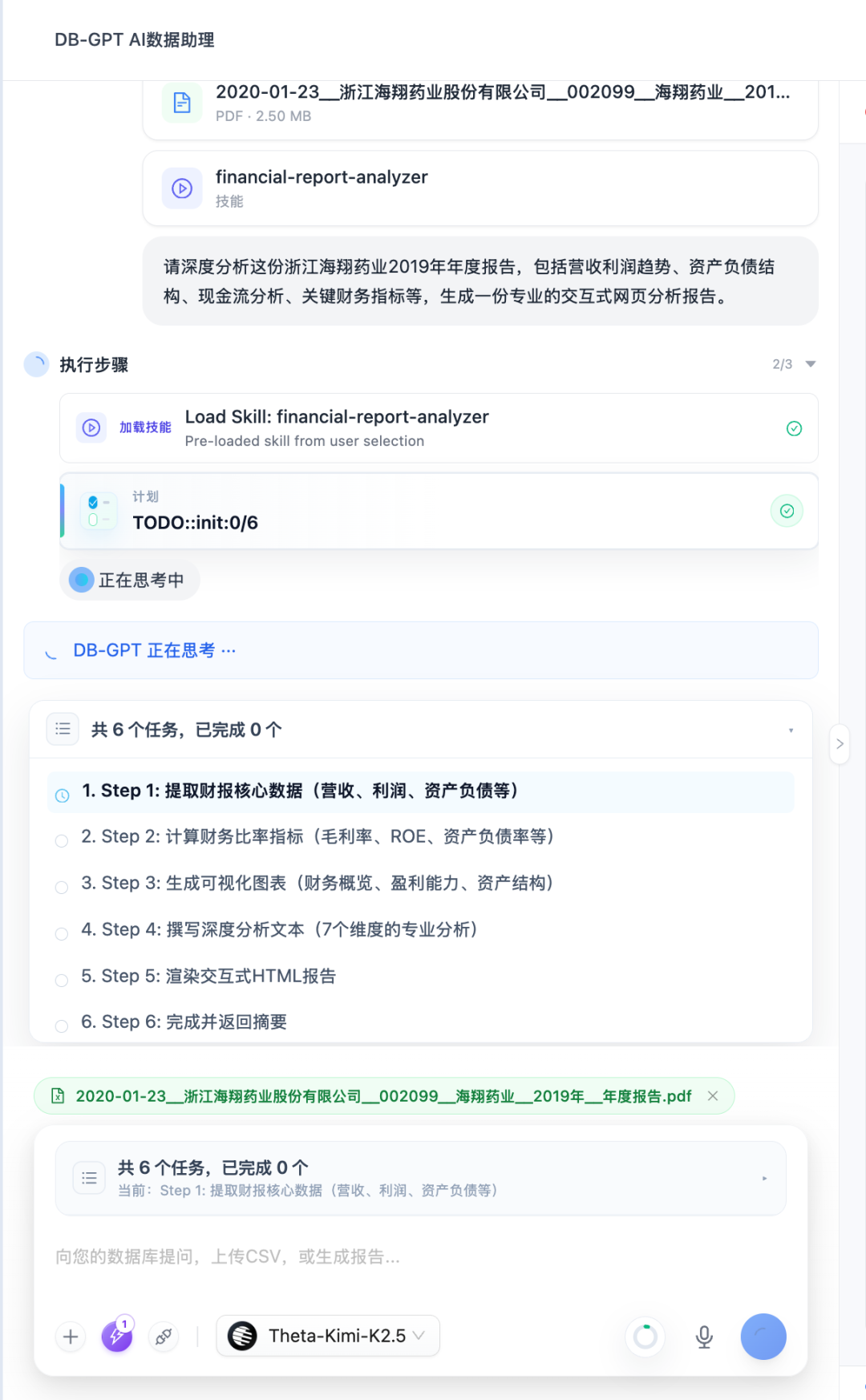
上下文窗口使用情况。
 🧱 模型、数据源与存储生态扩展
🧱 模型、数据源与存储生态扩展
V0.8.1 进一步扩展了 DB-GPT 周边生态,让团队可以更方便地复用已有模型、数据库、向量存储和缓存基础设施。
LiteLLM 嵌入式 AI GatewayDB-GPT 新增 LiteLLM 作为嵌入式代理 Provider,注册名为 proxy/litellm。它不是一个额外的代理服务,而是 DB-GPT 进程内直接调用 LiteLLM,让你通过统一入口访问 OpenAI、Anthropic、Vertex AI、Bedrock、Azure、Cohere、Mistral、Groq、Ollama 等 LiteLLM 支持的众多后端。
[[models.llms]]name = "anthropic/claude-3-5-sonnet-20241022"provider = "proxy/litellm"
新增向量检索与缓存后端
- Qdrant 向量检索:
支持高性能向量搜索场景。 - Valkey 向量存储:
支持使用 Valkey 和 valkey-search 构建向量检索链路。
- Valkey 缓存存储:
支持 LLM 响应缓存和 Embedding 缓存场景。 - 可配置距离度量:
向量检索的距离度量可按需配置。 - Valkey 向量客户端
CLIENT SETNAME:使 DB-GPT 的连接在 Valkey 监控工具中可被清晰识别。
新增数据源与模型支持
openGauss 数据源:补充连接、展示和使用文档支持。
StarRocks VARBINARY 与 BINARY 类型:完善 StarRocks 类型兼容。
MiniMax-M3:升级为 MiniMax Provider 默认模型,同时保留 MiniMax-M2.7 可选。
DeepSeek V4 Pro:新增模型支持。
 🚀 性能优化:面向大 Schema 和生产库的关键改进
🚀 性能优化:面向大 Schema 和生产库的关键改进V0.8.1 针对大 Schema、生产级数据库和索引链路做了重要性能优化。
- 数据源连接器缓存:
ConnectorManager.get_connector(db_name) 现在对构建好的连接器增加 TTL 缓存。在近 900 张表的生产 SQL Server 场景中,热缓存连接器查询从约 63 秒降至 10ms 以内。 - 按数据库粒度的索引锁:
避免 Schema 索引与刷新操作并发竞争,降低产生空索引的风险。 - 按 Chunk 粒度容错:
单个异常 Embedding Chunk 不再导致整个索引任务失败。 - MSSQL 元数据兼容:
针对 SQL Server 使用正确的 INFORMATION_SCHEMA 与扩展属性查询字段元数据。 - Milvus 2.5+ 兼容:
提升 Milvus 向量存储在新版本下的兼容性。
 🛡️ 安全与稳定性加固
🛡️ 安全与稳定性加固
本版本还包含多项面向生产环境的安全与稳定性增强:
~/.dbgpt/configs/.toml 本地 Profile 配置文件权限优化。
知识库模块接口补充认证依赖。
更严格校验 Skill 上传文件名、示例文件名和 Python 上传文件名。
限制个人 Skill 脚本执行,降低未受控执行风险。
Code Interpreter 临时脚本写入时显式使用 UTF-8 编码。
Markdown 知识库默认使用 size chunking,索引过程更可预测。
ReAct 解析器更好地兼容多步输出。
Chat DB 提示词明确说明当前检索到的表结构是 TOP-K 子集,提升全库元问题的回答准确性。
gpts_messages.content 字段以容纳更长的 Agent 消息(#3055)get_fields() 实现 SQL Server 兼容的 INFORMATION_SCHEMA 查询(#3039)本指南适用于从 v0.8.0 升级到 v0.8.1。
V0.8.1 的元数据变更为 1 个字段变更 + 3 张新增表。升级脚本已提供在 assets/schema/upgrade/v0_8_1/ 目录下:
与历史版本一致,增量脚本面向 MySQL。SQLite 用户请按惯例在升级前备份元数据库,新增表会在服务启动时自动创建。
准备工作
为避免数据丢失,升级前请务必备份元数据库。请根据数据库类型选择合适的备份方式,例如 MySQL 使用 mysqldump,SQLite 直接复制数据库文件。
元数据库升级
对于 SQLite 的升级,默认会自动升级表结构。对于 MySQL 的升级,需要手动执行 DDL ,其中 assets/schema/dbgpt.sql文件是当前版本完整的 DDL 文件,具体版本变更的 DDL 可以查看 assets/schema/upgrade下面的变更 DDL,例如您是从 v0.8.0升级到v0.8.1,可以执行下列的 DDL
mysql -h127.0.0.1 -uroot -p{your_password} < assets/schema/upgrade/v0_8_1/upgrade_to_v0.8.1.sql对于源码安装,建议通过 uv sync 更新依赖。
安装依赖
请根据你的部署方式安装或更新依赖。如果使用源码方式和默认配置安装:
uv sync --all-packages如需使用可选集成,请按需安装对应 Extra:
# LiteLLM 代理 Provideruv sync --all-packages --extra "proxy_litellm"# Qdrant 向量存储uv sync --all-packages --extra "storage_qdrant"# Valkey 缓存 / 向量存储uv sync --all-packages --extra "storage_valkey"
📖 官方文档地址
英文网址:http://docs.dbgpt.cn/docs/overview/
中文网址:https://www.yuque.com/eosphoros/dbgpt-docs/bex30nsv60ru0fmx
✨ 致谢
V0.8.1 的发布离不开社区开发者的持续贡献。
 新贡献者
新贡献者
V0.8.1 版本新增 13 位 新的贡献者:
🔥🔥感谢所有贡献者使这次发布成为可能!
@Aalron、@Anush008、@Aries-ckt、@Artoriasn、@Goodnight77、@JAE0Y2N、@RheagalFire、@atao2004、@chenliang15405、@daric93、@github0070070、@hankchrome、@honglei、@mryanzhicong、@octo-patch 和 @wolfkill
✨附录
快速开始:http://docs.dbgpt.cn/docs/next/quickstart/
53AI,企业落地大模型首选服务商
产品:场景落地咨询+大模型应用平台+行业解决方案
承诺:免费POC验证,效果达标后再合作。零风险落地应用大模型,已交付160+中大型企业
2026-06-18
企业AI两年了,为什么还没出现真正的 Killer Case?
2026-06-18
埃森哲和微软成立 FDE Practice:交付能力正在从"手艺"变成"可批发的产品
2026-06-18
AI 时代,实时入湖正在告别 ETL:从 Kafka 到 Iceberg 的架构减法
2026-06-18
AI 落地 KPI 怎么选?别看技术准确率,卡死这 3 个业务指标就够了
2026-06-17
AI Native 时代 —— 研发组织何去何从
2026-06-12
卡内基梅隆最新AI应用成熟度模型:AI转型最后拼的是组织基本功(附8项能力)
2026-06-11
企业AI场景全景拆解——100+落地场景,按业务域一网打尽
2026-06-11
咨询|FDE 为什么突然火了?到底是咨询顾问、还是AI工程师更适合做FDE呢?

2026-06-03
2026-03-23
2026-05-13
2026-03-26
2026-04-14
2026-04-09
2026-04-01
2026-04-16
2026-04-20
2026-05-26
2026-06-18
2026-06-11
2026-06-05
2026-06-02
2026-05-26
2026-03-21
2026-02-11
2026-01-21
回到顶部